Summary
As architecture, system, data management, and machine learning communities pay greater attention to innovative big data and AI or maching learning algorithms, architecture, and systems, the pressure of benchmarking rises. However, complexity, diversity, frequently changed workloads, and rapid evolution of big data and AI systems raise great challenges in benchmarking. First, for the sake of conciseness, benchmarking scalability, portability cost, reproducibility, and better interpretation of performance data, we need understand what are the most time-consuming classes of unit of computation among big data and AI workloads. Second, for the sake of fairness, the benchmarks must include diversity of data and workloads. Third, for co-design of software and hardware, we need simple but elegant abstractions that help achieve both efficiency and general-purpose. In addition, the benchmarks should be consistent across different communities.
We specify the common requirements of Big Data and AI only algorithmically in a paper-and pencil approach, reasonably divorced from individual implementations. We capture the differences and collaborations among IoT, edge, datacenter and HPC in handling Big Data and AI workloads. We consider each big data and AI workload as a pipeline of one or more classes of units of computation performed on initial or intermediate data inputs, each of which we call a data motif . For the first time, among a wide variety of big data and AI workloads, we identify eight data motifs (PACT 18 paper)— including Matrix, Sampling, Logic, Transform, Set, Graph, Sort and Statistic computation, each of which captures the common requirements of each class of unit of computation. Other than creating a new benchmark or proxy for every possible workload, we propose using data motif-based benchmarks—the combination of eight data motifs—to represent diversity of big data and AI workloads.
We release an open-source big data and AI benchmark suite—BigDataBench. The current version BigDataBench 5.0 provides 13 representative real-world data sets and 44 benchmarks. The benchmarks cover seven workload types including AI, online services, offline analytics, graph analytics, data warehouse, NoSQL, and streaming from three important application domains, Internet services (including search engines, social networks, e-commerce), recognition sciences, and medical sciences.. Our benchmark suite includes micro benchmarks, each of which is a single data motif, components benchmarks, which consist of the data motif combinations, and end-to-end application benchmarks, which are the combinations of component benchmarks. Meanwhile, data sets have great impacts on workloads behaviors and running performance (CGO’18). Hence, data varieties are considered with the whole spectrum of data types including structured, semi-structured, and unstructured data. Currently, the included data sources are text, graph, table, and image data. Using real data sets as the seed, the data generators—BDGS— generate synthetic data by scaling the seed data while keeping the data characteristics of raw data.
To achieve the consistency of benchmarks across different communities, we absorb state-of-the-art algorithms from the machine learning communities that considers the model’s prediction accuracy. For the benchmarking requirements of system and data management communities, we provide diverse implementations using the state-of-the-art techniques. For offline analytics, we provide Hadoop, Spark, Flink and MPI implementations. For graph analytics, we provide Hadoop, Spark GraphX, Flink Gelly and GraphLab implementations. For AI, we provide TensorFlow and Caffe implementations. For data warehouse, we provide Hive, Spark-SQL and Impala implementations. For NoSQL, we provide MongoDB and HBase implementations. For streaming, we provide Spark streaming and JStorm implementations.
For the architecture community, whatever early in the architecture design process or later in the system evaluation, it is time-consuming to run a comprehensive benchmark suite. The complex software stacks of the big data and AI workloads aggravate this issue. To tackle this challenge, we propose the data motif-based simulation benchmarks (IISWC’18 paper) for architecture communities, which speed up runtime 100 times while preserving system and micro-architectural characteristic accuracy. Also, we propose another methodology to reduce the benchmarking cost, we select a small number of representative benchmarks, called the BigDataBench subset according to workload characteristics from an architecture perspective. We provide the BigDataBench architecture subset (IISWC’14 paper) on the MARSSx86, gem5, and Simics simulator versions, respectively.
Modern datacenter computer systems are widely deployed with mixed workloads to improve system utilization and save cost. However, the throughput of latency-critical workloads is dominated by their worst-case performance-tail latency. To model this important application scenario, we propose an end-to-end application benchmark---DCMix to generate mixed workloads whose latencies range from microseconds to minutes with four mixed execution modes.
Modern Internet services workloads are notoriously complex in terms of industry-scale architecture fueled with machine learning algorithms. As a joint work with Alibaba, we release an end-to-end application benchmark---E-commerce Search to mimic complex modern Internet services workloads.
To measure and rank high performance AI computer systems (HPC AI) or AI supercomputers, we also release an HPC AI benchmark suite (AI500), consisting of micro benchmarks, each of which is a single data motif, and component benchmarks, e.g., resnet 50. We will release an AI500 list on BenchCouncil conferences soon.
Together with several industry partners, including Telecom Research Institute Technology, Huawei, Intel (China), Microsoft (China), IBM CDL, Baidu, Sina, INSPUR, ZTE and etc, we also release China’s first industry standard big data benchmark suite—-BigDataBench-DCA, which is a subset of BigDataBench 3.0.
Contributors
Prof. Jianfeng Zhan, ICT, Chinese Acadmey of Sciences, and BenchCouncil
Dr. Wanling Gao, ICT, Chinese Acadmey of Sciences
Dr. Lei Wang, ICT, Chinese Academy of Sciences
Chunjie Luo, ICT, Chinese Academy of Sciences
Dr. Chen Zheng, ICT, Chinese Academy of Sciences, and BenchCouncil
Dr. Zheng Cao, Alibaba
Hainan Ye, Beijing Academy of Frontier Sciences and BenchCouncil
Dr. Zhen Jia, Princeton University and BenchCouncil
Daoyi Zheng, Baidu
Shujie Zhang, Huawei
Haoning Tang, Tencent
Dr. Yingjie Shi
Zijian Ming, Tencent
Yuanqing Guo, Sohu
Yongqiang He, Dropbox
Kent Zhan, Tencent (Previously), WUBA(Currently)
Xiaona Li, Baidu
Bizhu Qiu, Yahoo!
Qiang Yang, BAFST
Jingwei Li, BAFST
Dr. Xinhui Tian, ICT, CAS
Dr. Gang Lu, BAFST
Xinlong Lin, BAFST
Rui Ren, ICT, CAS
Dr. Rui Han, ICT, CAS
Numbers
Benchmarking results are available soon.
Benchmark Methodology
We specify the common requirements of Big Data and AI only algorithmically in a paper-and pencil approach, reasonably divorced from individual implementations. We capture the differences and collaborations among IoT, edge, datacenter and HPC in handling Big Data and AI workloads. We consider each big data and AI workload as a pipeline of one or more classes of units of computation performed on initial or intermediate data inputs, each of which we call a data motif. Other than creating a new benchmark or proxy for every possible workload, we propose using data motif-based benchmarks—the combination of eight data motifs—to represent diversity of big data and AI workloads. Figure 1 summarizes our data motif-based scalable benchmarking methodology.
Figure 1 BigDataBench Benchmarking Methodology.
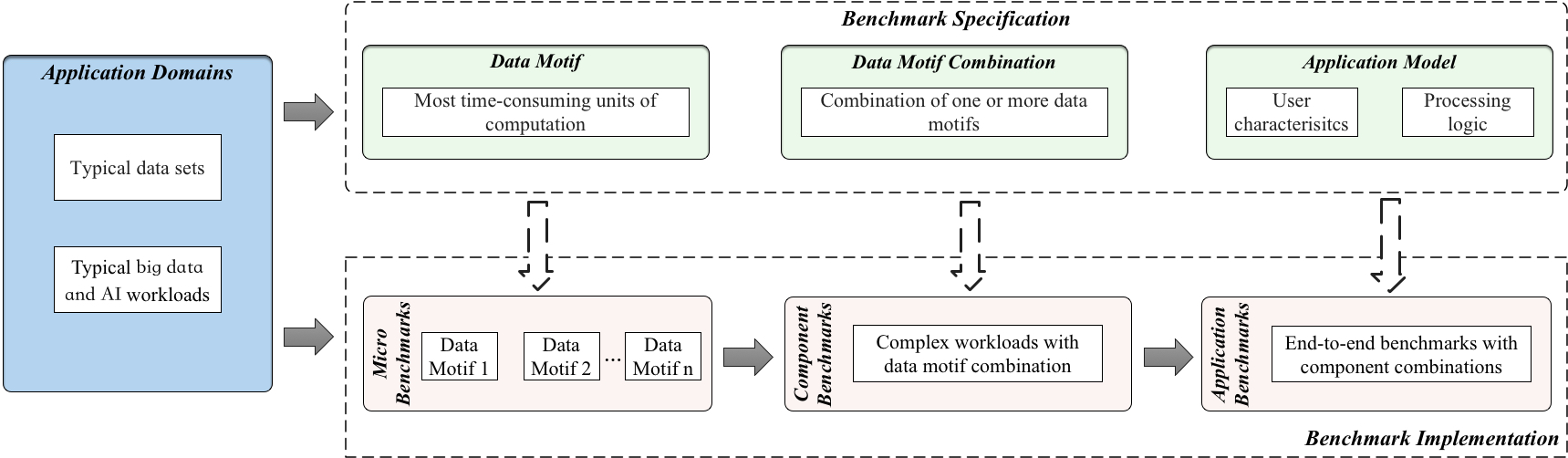
Benchmark Models
We provide three benchmark models for evaluating hardware, software system, and algorithms, respectively.
(1)The BigDataBench intact Model Division. This model is for hardware benchmarking. The users should run the implementation on their hardware directly without modification. The only allowed tuning includes hardware, OS and compiler settings.
(2)The BigDataBench constrained Model Division. This model is for software system benchmarking. The division specifies the model to be used and restricts the values of hyper parameters, e.g. batch size and learning rate. The users can implement the algorithms on their software platforms or frameworks by themselves.
(3)The BigDataBench free Model Division. This model is for algorithm benchmarking. The users are specified with using the same data set, with the emphasis being on advancing the state-of-the-art of algorithms.
Metrics
For the BigDataBench intact Model Division, the metrics include the wall clock time and energy efficiency to run benchmarks.
For the BigDataBench constrained model division, the metrics include the wall clock time and energy efficiency to run benchmarks. In addition, the values of hyper parameters should be reported for audition.
For the BigDataBench free model division, the metrics include the accuracy, and the wall clock time and energy efficiency to run benchmarks.
Benchmark Summary
BigDataBench is in fast expansion and evolution. Currently, we proposed benchmarks specifications modeling five typical application domains. The current version BigDataBench 5.0 includes real-world data sets and big data workloads, covering seven types. Table 1 summarizes the real-world data sets and scalable data generation tools included into BigDataBench 5.0, covering the whole spectrum of data types, including structured, semi-structured, and unstructured data, and different data sources, including text, graph, image, audio, video and table data. Table 2 and Table 3 present the micro benchmarks and component benchmarks in BigDataBench 5.0 from perspectives of involved data motif, application domain, workload type, data set and software stack. For some end users, they may just pay attention to big data application of a specific type. For example, they want to perform an apples-to-apples comparison of software stacks for offline analytics. They only need to choose benchmarks with the type of offline analytics.But if the users want to measure or compare big data systems and architecture, we suggest they cover all benchmarks.
Table 1 .The summary of data sets and data generation tools
| DATA SETS | DATA SIZE | SCALABLE DATA SET | |
|---|---|---|---|
| 1 | Wikipedia Entries | 4,300,000 English articles(unstructured text) | Text Generator of BDGS |
| 2 | Amazon Movie Reviews | 7,911,684 reviews(semi-structured text) | Text Generator of BDGS |
| 3 | Google Web Graph | 875713 nodes, 5105039 edges(unstructured graph) | Graph Generator of BDGS |
| 4 | Facebook Social Network | 4039 nodes, 88234 edges (unstructured graph) | Graph Generator of BDGS |
| 5 | E-commerce Transaction Data | table1:4 columns,38658 rows.
table2: 6columns, 242735 rows(structured table) |
Table Generator of BDGS |
| 6 | ProfSearch Person Resumes | 278956 resumes(semi-structured table) | Table Generator of BDGS |
| 7 | CIFAR-10 | 60000 color images with the dimension of 32*32 | Ongoing development |
| 8 | ImageNet | ILSVRC2014 DET image dataset(unstructured image) | Ongoing development |
| 9 | LSUN | One million labelled images, classified into 10 scene categories and 20 object categories | Ongoing development |
| 10 | TED Talks | Translated TED talks provided by IWSLT evaluation campaign | Ongoing development |
| 11 | SoGou Data | the corpus and search query data from So-Gou Labs(unstructured text) | Ongoing development |
| 12 | MNIST | handwritten digits database which has 60,000 training examples and 10,000 test examples(unstructured image) | Ongoing development |
| 13 | MovieLens Dataset | User’s score data for movies, which has 9,518,231 training examples and 386,835 test examples(semi-structured text) | Ongoing development |
Micro Benchmark
Table 2. The summary of the micro benchmarks in BigDataBench 5.0
|
Micro Benchmark |
Involved Data Motif |
Application Domain |
Workload Type |
Date Set |
Software Stack |
|
Sort |
Sort |
SE, SN, EC, MP, BI [1] |
Offline analytics |
Wikipedia entries |
Hadoop, Spark, Flink, MPI |
|
Grep |
Set |
SE, SN, EC, MP, BI |
Offline analytics |
Wikipedia entires |
Hadoop, Spark, Flink, MPI |
|
Streaming |
Random generate |
Spark streaming |
|||
|
WordCount |
Basic statistics |
SE, SN, EC, MP, BI |
Offline analytics |
Wikipedia entires |
Hadoop, Spark, Flink, MPI |
|
MD5 |
Logic |
SE, SN, EC, MP, BI |
Offline analytics |
Wikipedia entires |
Hadoop, Spark, MPI |
|
Connected Component |
Graph |
SN |
Graph analytics |
Facebook social network |
Hadoop, Spark, Flink, GraphLab, MPI |
|
RandSample |
Sampling |
SE, MP, BI |
Offline analytics |
Wikipedia entires |
Hadoop, Spark, MPI |
|
FFT |
Transform |
MP |
Offline analytics |
Two-dimensional matrix |
Hadoop, Spark, MPI |
|
Matrix Multiply |
Matrix |
SE, SN, EC, MP, BI |
Offline analytics |
Two-dimensional matrix |
Hadoop, Spark, MPI |
|
Read |
Set |
SE, SN, EC |
NoSQL |
ProfSearch resumes |
HBase, MongoDB |
|
Write |
Set |
SE, SN, EC |
NoSQL |
ProfSearch resumes |
HBase, MongoDB |
|
Scan |
Set |
SE, SN, EC |
NoSQL |
ProfSearch resumes |
HBase, MongoDB |
|
OrderBy |
Set |
EC |
Data warehouse |
E-commerce transaction |
Hive, Spark-SQL, Impala |
|
Aggregation |
Set |
EC |
Data warehouse |
E-commerce transaction |
Hive, Spark-SQL, Impala |
|
Project |
Set |
EC |
Data warehouse |
E-commerce transaction |
Hive, Spark-SQL, Impala |
|
Filter |
Set |
EC |
Data warehouse |
E-commerce transaction |
Hive, Spark-SQL, Impala |
|
Select |
Set |
EC |
Data warehouse |
E-commerce transaction |
Hive, Spark-SQL, Impala |
|
Union |
Set |
EC |
Data warehouse |
E-commerce transaction |
Hive, Spark-SQL, Impala |
|
Convolution |
Transform |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
Fully Connected |
Matrix |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
Relu |
Logic |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
Sigmoid |
Matrix |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
Tanh |
Matrix |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
MaxPooling |
Sampling |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
AvgPooling |
Sampling |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
CosineNorm |
Basic Statistics |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
BatchNorm |
Basic Statistics |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
|
Dropout |
Sampling |
SN, EC, MP, BI |
AI |
Cifar, ImageNet |
TensorFlow, Caffe |
[1]SE (Search Engine), SN (Social Network), EC (e-commerce), BI (Bioinformatics), MP (Multimedia Processing).
Component Benchmark
The component benchmarks cover a set of big data and AI problems, each defined by a dataset , an algorithm and its implementations.
Image classification
Workloads type: AIApplication domains:
Dataset: Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. S.; Berg, A. C.; Fei-Fei, L. (2015). ImageNet Large Scale Visual Recognition Challenge, International Journal of Computer Vision (IJCV).
Algorithm: He, K.; Zhang, X.; Ren, S; Sun, J. (2015), 'Deep Residual Learning for Image Recognition', CoRR abs/1512.03385.
Involved data motifs:
Software stacks:
Implementation Contributors:
Image generation
Workloads type: AIApplication domains:
Dataset: Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao. LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop. Corr, abs/1506.03365, 2015.
Algorithm: Arjovsky, Martin, Chintala, Soumith, and Bottou, L´eon. Wasserstein gan. arXiv preprint arXiv:1701.07875, 2017.
Involved data motifs:
Software stacks:
Implementation Contributors:
Text-to-Text Translation
Workloads type: AIApplication domains:
Dataset: WMT English-German from Bojar, O.; Buck, C.; Federmann, C.; Haddow, B.; Koehn, P.; Monz, C.; Post, M.; Specia, L., ed. (2014), Proceedings of the Ninth Workshop on Statistical Machine Translation, Association for Computational Linguistics, Baltimore, Maryland, USA.
Algorithm: Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, L.; Polosukhin, I. (2017), 'Attention Is All You Need', CoRR abs/1706.03762.
Involved data motifs:
Software stacks:
Implementation Contributors:
Image-to-Text
Workloads type: AIApplication domains:
Dataset: MS COCO dataset, http://cocodataset.org/
Algorithm: "Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge." Oriol Vinyals, Alexander Toshev, Samy Bengio, Dumitru Erhan. IEEE transactions on pattern analysis and machine intelligence (2016).
Involved data motifs:
Software stacks:
Implementation Contributors:
Image-to-Image
Workloads type: AIApplication domains:
Dataset: M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016
Algorithm: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Involved data motifs:
Software stacks:
Implementation Contributors:
Speech-to-Text
Workloads type: AIApplication domains:
Dataset: Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. (2015), Librispeech: An ASR corpus based on public domain audio books, in '2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)', pp. 5206-5210.
Algorithm: Amodei, D.; Anubhai, R.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Chen, J.; Chrzanowski, M.; Coates, A.; Diamos, G.; Elsen, E.; Engel, J.; Fan, L.; Fougner, C.; Han, T.; Hannun, A. Y.; Jun, B.; LeGresley, P.; Lin, L.; Narang, S.; Ng, A. Y.; Ozair, S.; Prenger, R.; Raiman, J.; Satheesh, S.; Seetapun, D.; Sengupta, S.; Wang, Y.; Wang, Z.; Wang, C.; Xiao, B.; Yogatama, D.; Zhan, J.; Zhu, Z. (2015), 'Deep Speech 2: End-to-End Speech Recognition in English and Mandarin', CoRR abs/1512.02595.
Involved data motifs:
Software stacks:
Implementation Contributors:
Face embedding
Workloads type: AIApplication domains:
Dataset: G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007. 5
Algorithm: FaceNet: A Unified Embedding for Face Recognition and Clustering
Involved data motifs:
Software stacks:
Implementation Contributors:
Object detection
Workloads type: AIApplication domains:
Dataset: Lin, T.-Y.; Maire, M.; Belongie, S. J.; Bourdev, L. D.; Girshick, R. B.; Hays, J.; Perona, P.; Ramanan, D.; Dollбr, P.; Zitnick, C. L. (2014), 'Microsoft COCO: Common Objects in Context', CoRR abs/1405.0312.
Algorithm: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Involved data motifs:
Software stacks:
Implementation Contributors:
Recommendation
Workloads type: AIApplication domains:
Dataset: Harper, F. M.; Konstan, J. A. (2015), 'The MovieLens Datasets: History and Context', ACM Trans. Interact. Intell. Syst. 5(4), 19:1--19:19.
Algorithm: Koren, Y., Bell, R.M., Volinsky, C. Matrix factorization techniques for recommender systems. IEEE Computer 42(8), 30–37 (2009)
Involved data motifs:
Software stacks:
Implementation Contributors:
Workloads type:
Application domains:
Dataset:
Algorithm:
Involved data motifs:
Software stacks:
Implementation Contributors:
PageRank
Workloads type: Graph AnalyticsApplication domains:
Dataset: Google web graph. http://snap.stanford.edu/data/web-Google.htm
Algorithm: L. Page, S. Brin, R. Motwani, and T. Winograd. The pagerank citation ranking: Bringing order to the web. Technical report, Stanford University, Stanford, CA, 1998. 17, 18, 88
Involved data motifs:
Software stacks:
Implementation Contributors:
Graph Model
Workloads type: Graph AnalyticsApplication domains:
Dataset: Wikipedia English articles. https://dumps.wikimedia.org/
Algorithm: D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation. the Journal of machine Learning research, 3:993–1022, 2003.
Involved data motifs:
Software stacks:
Implementation Contributors:
Clustering
Workloads type: Big DataApplication domains:
Dataset: Facebook social network. http://snap.stanford.edu/data/egonets-Facebook.html
Algorithm: Krishna, K., Murty, M. N. (1999). Genetic K-means algorithm. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 29(3), 433-439.
Involved data motifs:
Software stacks:
Implementation Contributors:
Classification
Workloads type:Application domains:
Dataset: Amazon movie review. http://snap.stanford.edu/data/web-Movies.html
Algorithm: Rish, I. (2001, August). An empirical study of the naive Bayes classifier. In IJCAI 2001 workshop on empirical methods in artificial intelligence (Vol. 3, No. 22, pp. 41-46). New York: IBM.
Involved data motifs:
Software stacks:
Implementation Contributors:
Feature Exaction
Workloads type:Application domains:
Dataset: ImageNet. http://www.image-net.org
Algorithm: Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2), 91-110.
Involved data motifs:
Software stacks:
Implementation Contributors:
Search Engine Indexing
Workloads type:Application domains:
Dataset: Wikipedia English articles. https://dumps.wikimedia.org/
Algorithm: Black, Paul E., inverted index, Dictionary of Algorithms and Data Structures, U.S. National Institute of Standards and Technology Oct 2006. Verified Dec 2006.
Involved data motifs:
Software stacks:
Implementation Contributors:
Application Benchmark
DCMix
Modern datacenter computer systems are widely deployed with mixed workloads to improve system utilization and save cost. However, the throughput of latency-critical workloads is dominated by their worst-case performance-tail latency. To model this important application scenario, we propose an end-to-end application benchmark---DCMix to generate mixed workloads whose latencies range from microseconds to minutes with four mixed execution modes.
E-commerce search
Modern Internet services workloads are notoriously complex in terms of industry-scale architecture fueled with machine learning algorithms. As a joint work with Alibaba, we release an end-to-end application benchmark---E-commerce Search to mimic complex modern Internet services workloads.
HPC AI Benchmark Suite.
Since deep learning has made unprecedented success in a wide spectrum of commercial AI areas such as image recognition, natural language processing and auto driving, the HPC community started using deep learning to solve scientific problems (e.g. extreme weather prediction). These emerging AI workloads with new performance characteristics require a new yard stick to design next generation HPC system. In this context, we present AI500 benchmark, a benchmark suite for evaluating HPC AI systems.AI500 benchmark consist of several micro benchmarks and component benchmarks.
Evolution
As shown in Figure 2, the evolution of BigDataBench has gone through three major stages: At the first stage, we released three benchmarks suites, BigDataBench 1.0 (6 workloads from Search engine), DCBench 1.0 (11 workloads from data analytics), and CloudRank 1.0(mixed data analytics workloads).
At the second stage, we merged the previous three benchmark suites and release BigDataBench 2.0 , through investigating the top three important application domains from internet services in terms of the number of page views and daily visitors. BigDataBench 2.0 includes 6 real-world data sets, and 19 big data workloads with different implementations, covering six application scenarios: micro benchmarks, Cloud OLTP, relational query, search engine, social networks, and e-commerce. Moreover, BigDataBench 2.0 provides several big data generation tools–BDGS– to generate scalable big data, e.g, PB scale, from small-scale real-world data while preserving their original characteristics.
BigDataBench 3.0 is a multidisciplinary effort. It includes 6 real-world, 2 synthetic data sets, and 32 big data workloads, covering micro and application benchmarks from typical application domains, e. g., search engine, social networks, and e-commerce. As to generating representative and variety of big data workloads, BigDataBench 3.0 focuses on units of computation that frequently appear in Cloud OLTP, OLAP, interactive and offline analytics.
Figure 2: BigDataBench Evolution
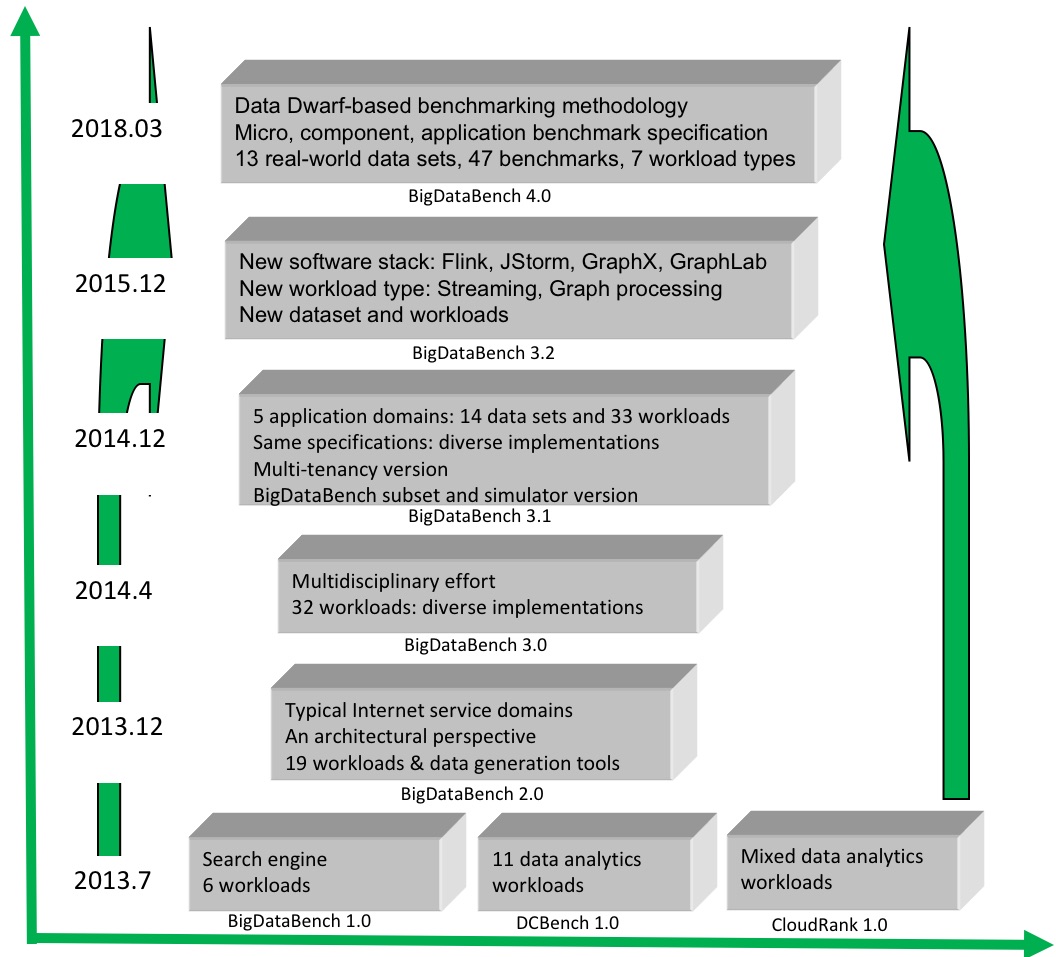
Previous releases
BigDataBench 3.2 http://prof.ict.ac.cn/BigDataBench/old/3.2/
BigDataBench 3.1 http://prof.ict.ac.cn/BigDataBench/old/3.1/
BigDataBench 3.0 http://prof.ict.ac.cn/BigDataBench/old/3.0/
BigDataBench 2.0 http://prof.ict.ac.cn/BigDataBench/old/2.0/
BigDataBench 1.0 http://prof.ict.ac.cn/BigDataBench/old/1.0/
DCBench 1.0 http://prof.ict.ac.cn/DCBench/
CloudRank 1.0 http://prof.ict.ac.cn/CloudRank/
Handbook
Handbook of BigDataBench [BigDataBench-handbook]
Q &A
More questions & answers are available from the handbook of BigDataBench.
Contacts (Email)
- gaowanling@ict.ac.cn
- luochunjie@ict.ac.cn
- zhanjianfeng@ict.ac.cn
- wanglei_2011@ict.ac.cn
License
BigDataBench is available for researchers interested in big data. Software components of BigDataBench are all available as open-source software and governed by their own licensing terms. Researchers intending to use BigDataBench are required to fully understand and abide by the licensing terms of the various components. BigDataBench is open-source under the Apache License, Version 2.0. Please use all files in compliance with the License. Our BigDataBench Software components are all available as open-source software and governed by their own licensing terms. If you want to use our BigDataBench you must understand and comply with their licenses. Software developed externally (not by BigDataBench group)
- Boost: http://www.boost.org/doc/libs/1_43_0/more/getting_started/unix-variants.html
- GCC: http://gcc.gnu.org/releases.html
- GSL: http://www.gnu.org/software/gsl/
- Graph500 : http://www.graph500.org/referencecode
- Hadoop: http://www.apache.org/licenses/LICENSE-2.0
- HBase : http://hbase.apache.org/
- Hive: http://hive.apache.org/
- Impala: https://github.com/cloudera/impala
- MySQL : http://www.mysql.com/
- Mahout: http://www.apache.org/licenses/LICENSE-2.0
- Mpich: http://www.mpich.org/
- Nutch : http://www.apache.org/licenses/LICENSE-2.0
- Parallel Boost Graph Library : http://www.osl.iu.edu/research/pbgl/software/
- Spark: http://spark.incubator.apache.org/
- Shark: http://shark.cs.berkeley.edu/
- Scala: http://www.scala-lang.org/download/2.9.3.html
- Zookeeper: http://zookeeper.apache.org/
Software developed internally (by BigDataBench group) BigDataBench_4.0 License BigDataBench_4.0 Suite Copyright (c) 2013-2018, ICT Chinese Academy of Sciences All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistribution of source code must comply with the license and notice disclaimers
- Redistribution in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimers in the documentation and/or other materials provided by the distribution.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE ICT CHINESE ACADEMY OF SCIENCES BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.